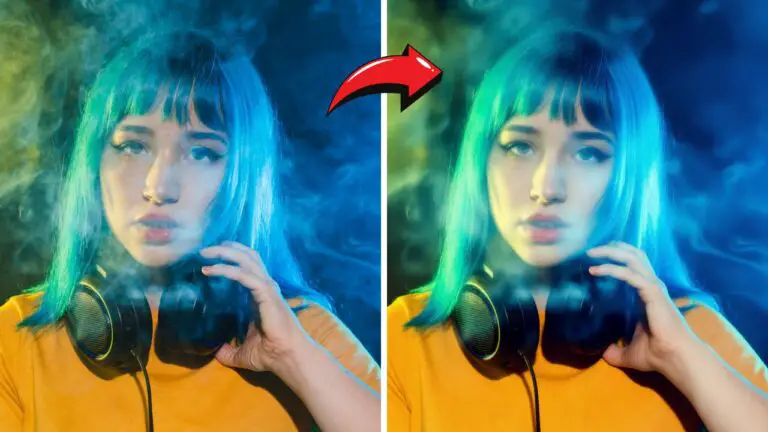Flux Kontext vs Qwen Edit 2509: The ULTIMATE Pose Transfer Test (Shocking Results)
Pose transfer is the art of taking a subject from one image and faithfully reproducing their identity, style, and intent in the pose of another. While recent tools have made this easier, the real challenge is achieving accuracy in difficult poses and maintaining facial consistency at practical resolutions.
This article compares Qwen Image Edit (v2509) and Flux Kontext, then walks you through a hands-on Flux Kontext workflow in ComfyUI with actionable tips for tricky scenarios.
Qwen Image Edit (v2509): What Changed—and What It Means
- Multiple inputs (up to 3): You can now provide several images at once—no need to stitch sources into a single canvas.
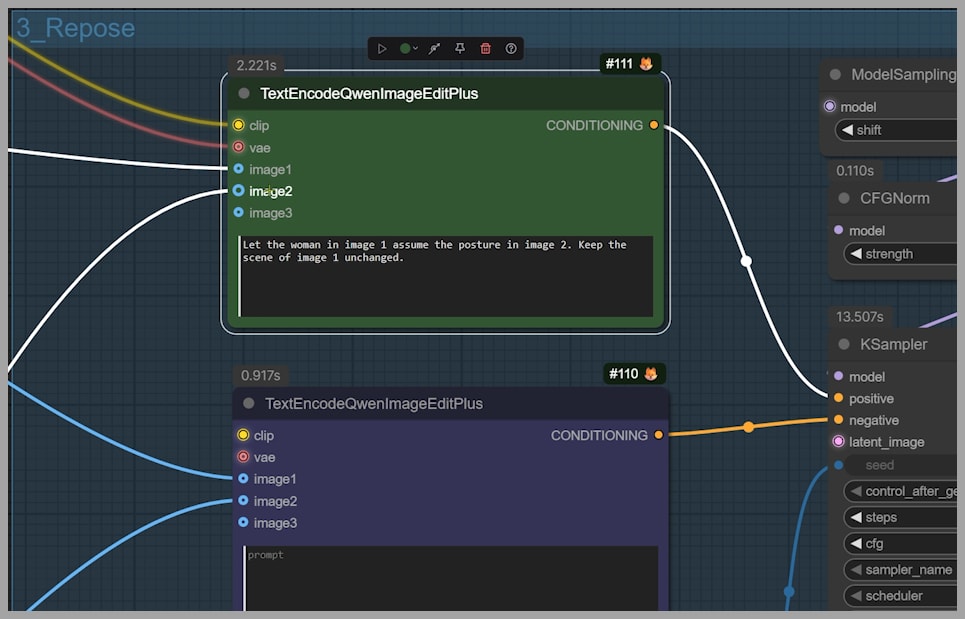
- Understands OpenPose skeletons: Supplying an OpenPose image now signals a pose-transfer task directly—no LoRA required.
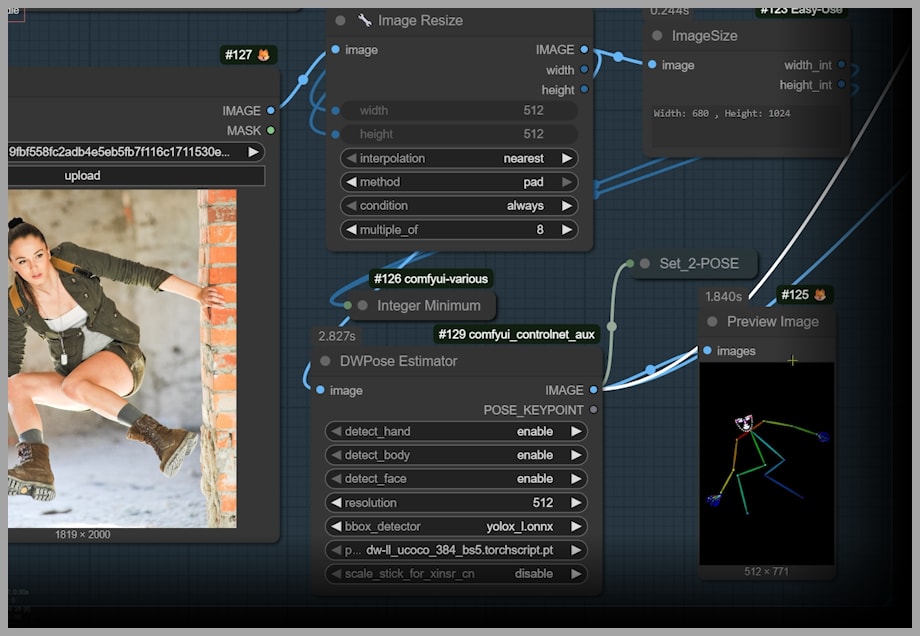
- No more stitched outputs: Earlier workflows forced you to stitch inputs and crop the final, tiny result (e.g., ~586×888); that’s gone.
But there are limits:
- Resolution ceiling: Outputs hover around ~1 MP reliably; pushing beyond (e.g., 960×1440 ≈ 1.4 MP) can introduce visible artifacts (often along edges).

- “AI-polish” look: Results can lose identity/facial consistency compared to Flux Kontext.
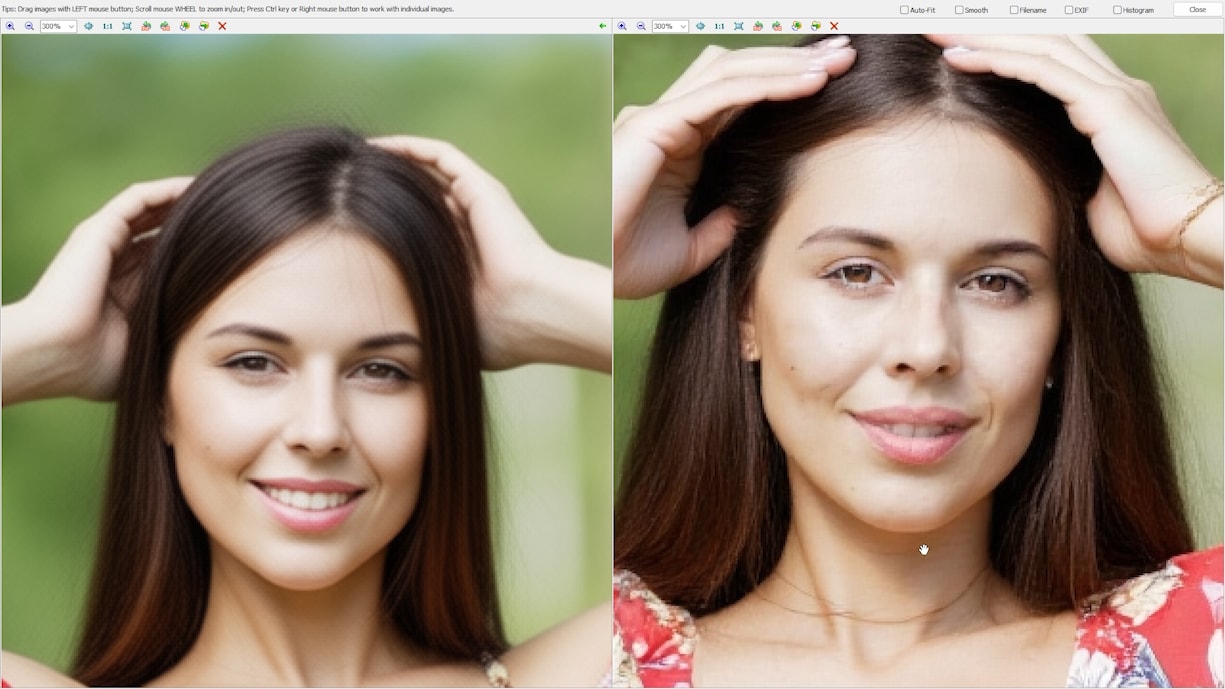
- Speed vs detail trade-off: With a Lightning “4 Steps” LoRA, Qwen is very fast, but jumping to ~20 steps (without Lightning) restores more detail.

Why Flux Kontext Still Matters
From extensive side-by-side testing—especially on difficult compositions—Flux Kontext typically reproduces the target pose more faithfully and preserves facial identity better:
- Accuracy on subtle gestures: Kontext captured small cues (e.g., an index finger resting on the lower lip) that Qwen missed.

- Resolution headroom: Kontext remains stable up to roughly ~2 MP, giving you more room for print-quality outputs.
My preference: I lean toward Flux Kontext because it maintains facial consistency. Lost micro-details can be recovered later; a warped identity is far harder to fix.
Head-to-Head Summary
- Pose fidelity: Kontext usually wins, especially on complex pose changes; Qwen has occasional wins (e.g., standing → prone).
- Identity consistency: Kontext generally preserves facial features more reliably.
- Resolution: Kontext is comfortable up to ~2 MP; Qwen degrades past ~1 MP.
- Speed: Qwen can be very fast with Lightning LoRA and low steps; Kontext benefits from caching (TeaCache) but is slower.
The Flux Kontext Workflow in ComfyUI (Overview)
We’ll build a robust workflow that guides Kontext with ControlNet and carefully curated references:
Core ideas:
- Separate pose from identity.
- Pose comes from ControlNet OpenPose (skeleton) and ControlNet Depth.
- Identity/style comes from your reference images (ReferenceLatent nodes).
- Pre-shape the depth.
- Use SD1.5 to synthesize an intermediate image close to the target pose; then extract a depth map from it.
- Stabilize weak links.
- Blur confusing regions (hands, mismatched faces) before depth extraction to reduce “false” geometry.
- Nudge the generator with a prompt.
- Include intent keywords like “deblur” and a short pose description to counter any soft inputs.
- Iterate smartly, not blindly.
- Use TeaCache to accelerate Kontext, rel_l1_thresh for quick pose checks, then dial back for final quality.
If you found this article helpful, feel free to share it with your community—and keep exploring. The more thoughtfully you guide Kontext, the more convincingly it brings complex poses to life.
Gain exclusive access to advanced ComfyUI workflows and resources by joining our community now!