Overcoming DALL-E’s Limitations with Midjourney
DALL-E stands out as a remarkable AI tool for image generation, akin to ChatGPT’s prowess in text. It’s adept at understanding and following prompts with precision, though its artistic flair can sometimes feel limited.
On the flip side, Midjourney operates like an inspired artist—less focused on literal comprehension but excelling in creating images with rich texture and aesthetic appeal.
Could we, then, blend DALL-E’s semantic precision with Midjourney’s artistic strengths? This exploration delves into the practicalities of such a synergy.
The Solo Journey with DALL-E
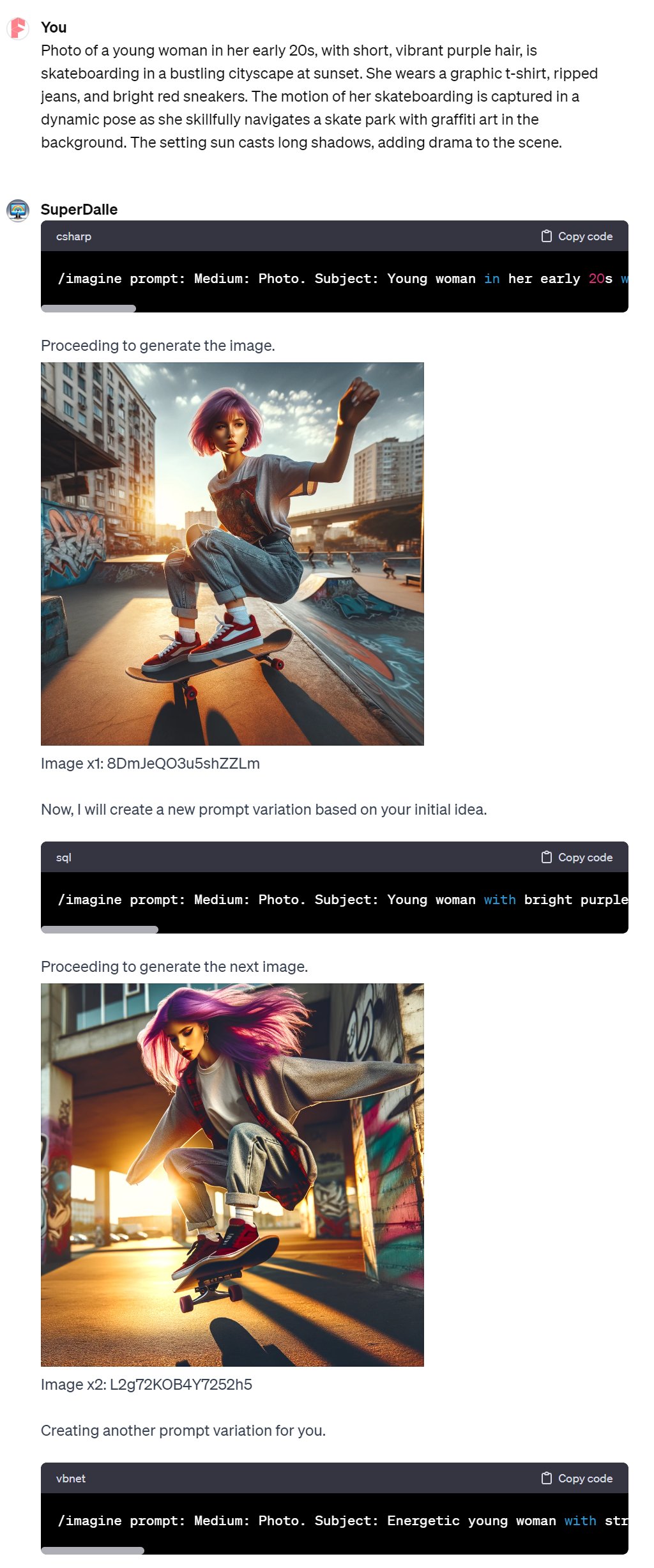
DALL-E’s capabilities in generating images based on detailed prompts are impressive, yet it falters in areas like portraying human skin and eyes, often resulting in textures that appear somewhat artificial. Observe the following example:
Prompt: Photo of a young woman in her early 20s, with short, vibrant purple hair, is skateboarding in a bustling cityscape at sunset. She wears a graphic t-shirt, ripped jeans, and bright red sneakers. The motion of her skateboarding is captured in a dynamic pose as she skillfully navigates a skate park with graffiti art in the background. The setting sun casts long shadows, adding drama to the scene.
The image, while faithful to the description, reveals a certain plastic-like quality in the skin and a somewhat distorted appearance in the eyes upon closer inspection.
Midjourney’s Artistic Solo
Now, let’s consider the same scenario through Midjourney’s lens.
Unlike DALL-E 3, Midjourney prefers a more streamlined prompt style, free from unnecessary linguistic elements like prepositions and articles. For instance:
Medium: Photo. Subject: Young woman in her early 20s with short, vibrant purple hair, skateboarding in a bustling cityscape at sunset, wearing a graphic t-shirt, ripped jeans, bright red sneakers. Dynamic pose as she navigates a skate park with graffiti art. Emotion: Energetic. Lighting: Sunset casting long shadows. Scene: Skate park in a cityscape, graffiti art in background. Style: Realistic, dynamic motion capture –ar 1:1
To streamline the creation of Midjourney prompts in ChatGPT, I’ve developed a tool named SuperDalle. It generates both images and suitable Midjourney prompts, as elaborated in this article:
👉 SuperDalle GPT: Revolutionizing DALL-E 3!
Here are the images and the corresponding Midjourney prompts from SuperDalle:
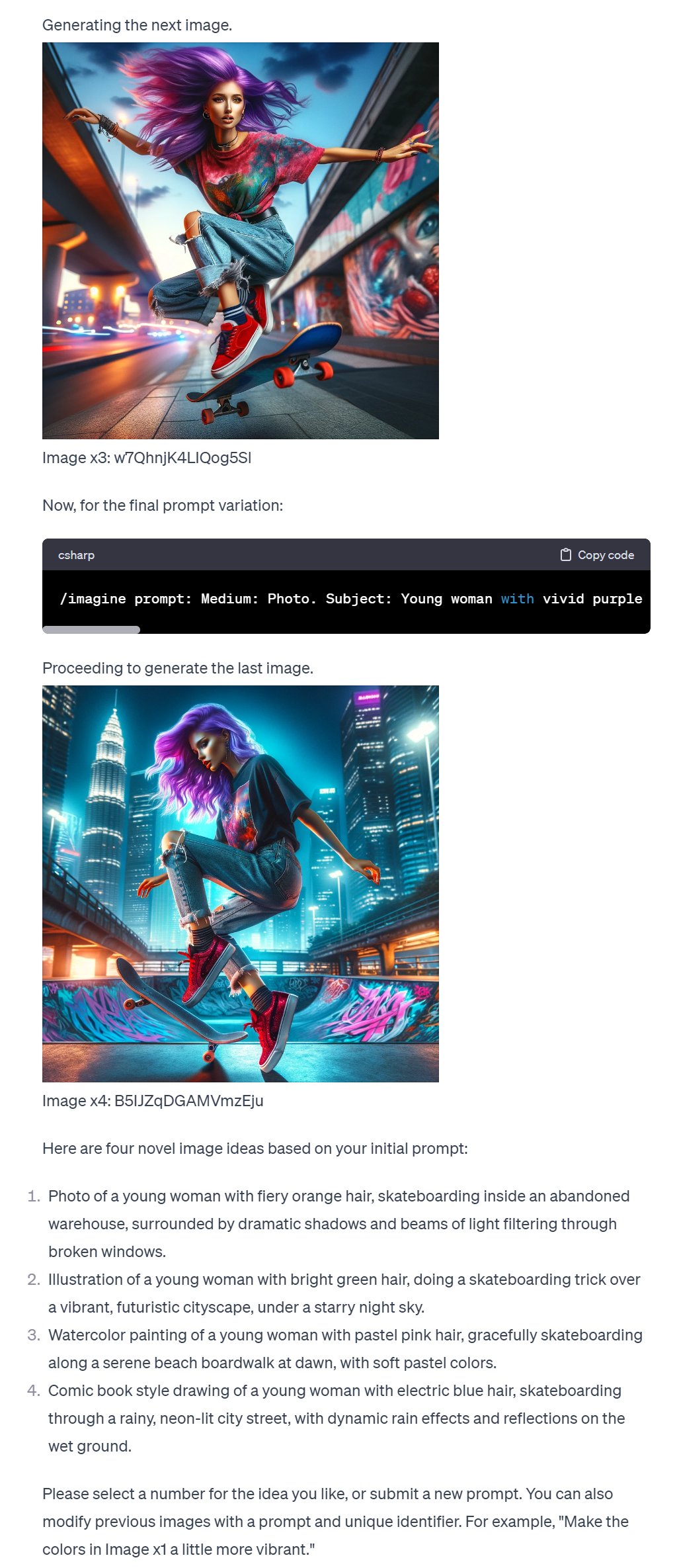
Selecting the first image as it closely aligns with our prompt, we venture into how Midjourney reshapes this vision. Upon inputting the Midjourney prompt for this image, we are greeted with these four distinct creations:
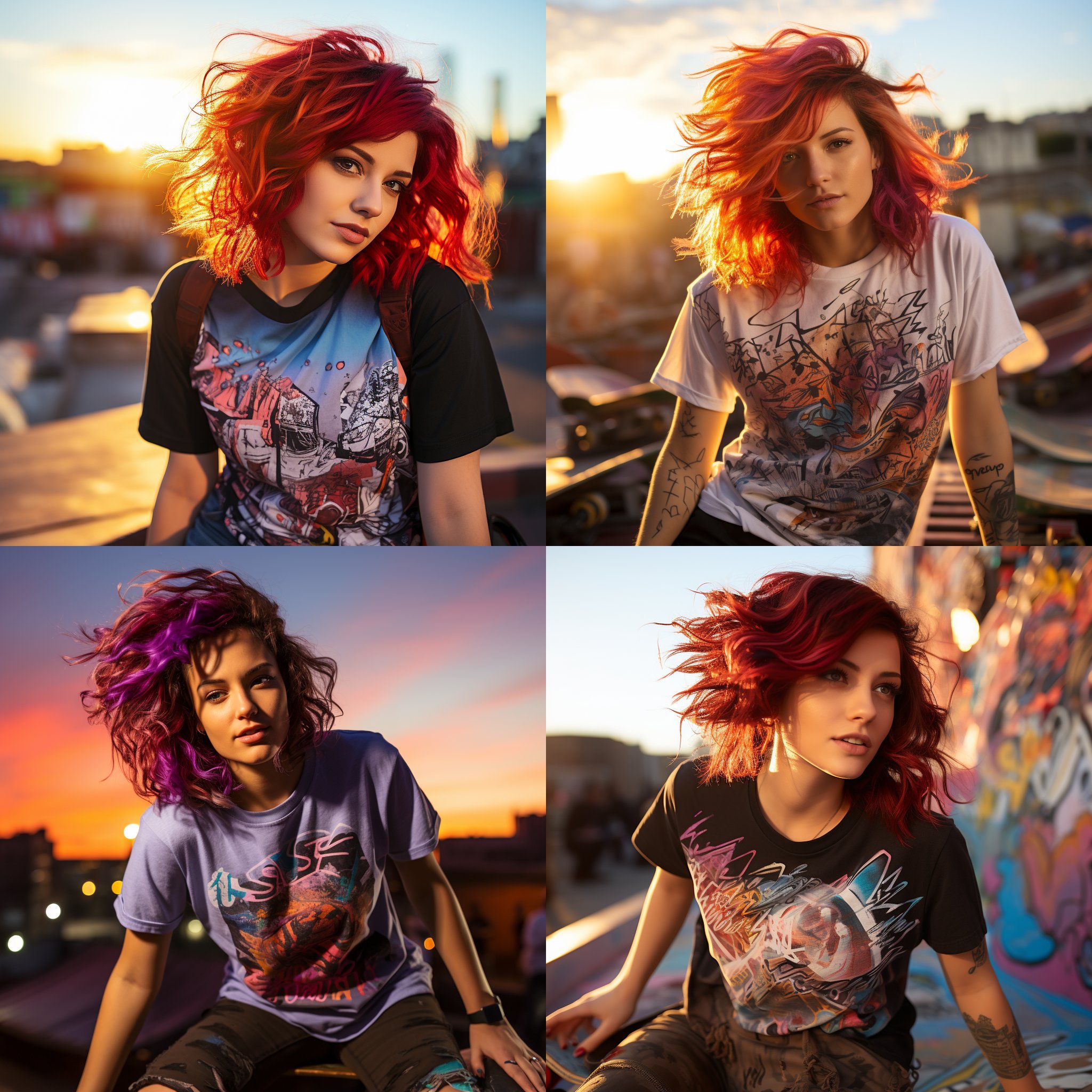
While the skin texture and the ambient lighting in these images are commendable, they diverge significantly from our intended narrative. Notably, the portrayal of the girls misses the mark—they are not depicted in a skateboarding stance as envisaged. This discrepancy isn’t attributed to the aspect ratio either. To illustrate this point, I adjusted the aspect ratio to 9:16, resulting in the following visualization:

Synergizing DALL-E and Midjourney
This is where the fusion of DALL-E and Midjourney shines. Using a DALL-E generated image as a reference with a higher weight and then processing it through Midjourney produces intriguing results:
Medium: Photo. Subject: Young woman in her early 20s with short, vibrant purple hair, skateboarding in a bustling cityscape at sunset, wearing a graphic t-shirt, ripped jeans, bright red sneakers. Dynamic pose as she navigates a skate park with graffiti art. Emotion: Energetic. Lighting: Sunset casting long shadows. Scene: Skate park in a cityscape, graffiti art in background. Style: Realistic, dynamic motion capture –ar 1:1 –s 1000 –v 5.2 –iw 2

Focusing on the image in the lower right corner, I further refined it, leading to these four variations:

Zooming in on the bottom left image:

If necessary, Midjourney’s inpainting feature can be employed to better align with the original prompt.
Conclusion
The exceptional semantic comprehension of DALL-E can be attributed to its foundation in the Transformer model, renowned for its proficiency in understanding and generating content based on intricate prompts. In contrast, Midjourney, sharing similarities with Stable Diffusion, is built on the Diffusion model, which excels in crafting images with a more artistic and textural richness.
Our exploration reveals that in certain scenarios, it’s feasible to amalgamate the distinct strengths of these two models. This fusion allows us to create images that are not only semantically precise but also aesthetically rich and artistically nuanced.
However, it’s crucial to recognize that this synergistic approach isn’t universally applicable. The key lies in understanding the unique capabilities and limitations of both the Midjourney and DALL-E. With this knowledge, we can identify the appropriate contexts where merging DALL-E’s semantic accuracy with Midjourney’s artistic flair is most effective, unlocking new possibilities in AI-driven image creation.





