How to Use ChatGPT for Website Data Mining: Practical Examples
The ascendancy of ChatGPT affirms the undisputed power of data. It owes its vast reservoir of knowledge to its capacity to sift through millions of data points online, and train itself into an expansive language model. This marks an era where command over valuable data signifies the strength of voice in the world of artificial intelligence.
As average citizens, we interact with data on a daily basis. Any decision-making process, such as industry analysis, requires us to accumulate and dissect a significant quantity of data. Indeed, we are navigating a data-driven epoch.
Traditionally, the process of harvesting vast amounts of data required proficiency in programming languages—Python being a favored choice for data crawling and analysis.
However, the advent of ChatGPT has revolutionized this scenario. Now, even those devoid of coding skills can accomplish intricate web crawling tasks simply by engaging in a conversation with ChatGPT.
This piece aims to provide a comprehensive guide on leveraging ChatGPT to extract data from websites, using tangible examples.
Let us delve into the details.
Necessary Preparations
To extract data from websites, a fundamental requirement is an internet connection. It is crucial to remember that standalone ChatGPT lacks networking capabilities. Therefore, in order to exploit the networking capacity of ChatGPT, you need to first become a ChatGPT Plus user. Upgrading to a Plus user comes with several advantages:
- Stable and seamless access, even during periods of high traffic
- Access to the higher-performing GPT-4 model
- Priority admission to the most recent features of ChatGPT
- Freedom to install any plugin from the plugin store
If you’re contemplating the upgrade to ChatGPT Plus, you might find this post of mine helpful:
On the other hand, if you are a current ChatGPT Plus member and unsure about how to install the plugins I will discuss shortly, refer to this post of mine:
Moving forward, I will guide you through the process of data crawling on a website, commonly used for teaching purposes. This website, consisting of 10 pages, hosts several renowned quotes on each page.
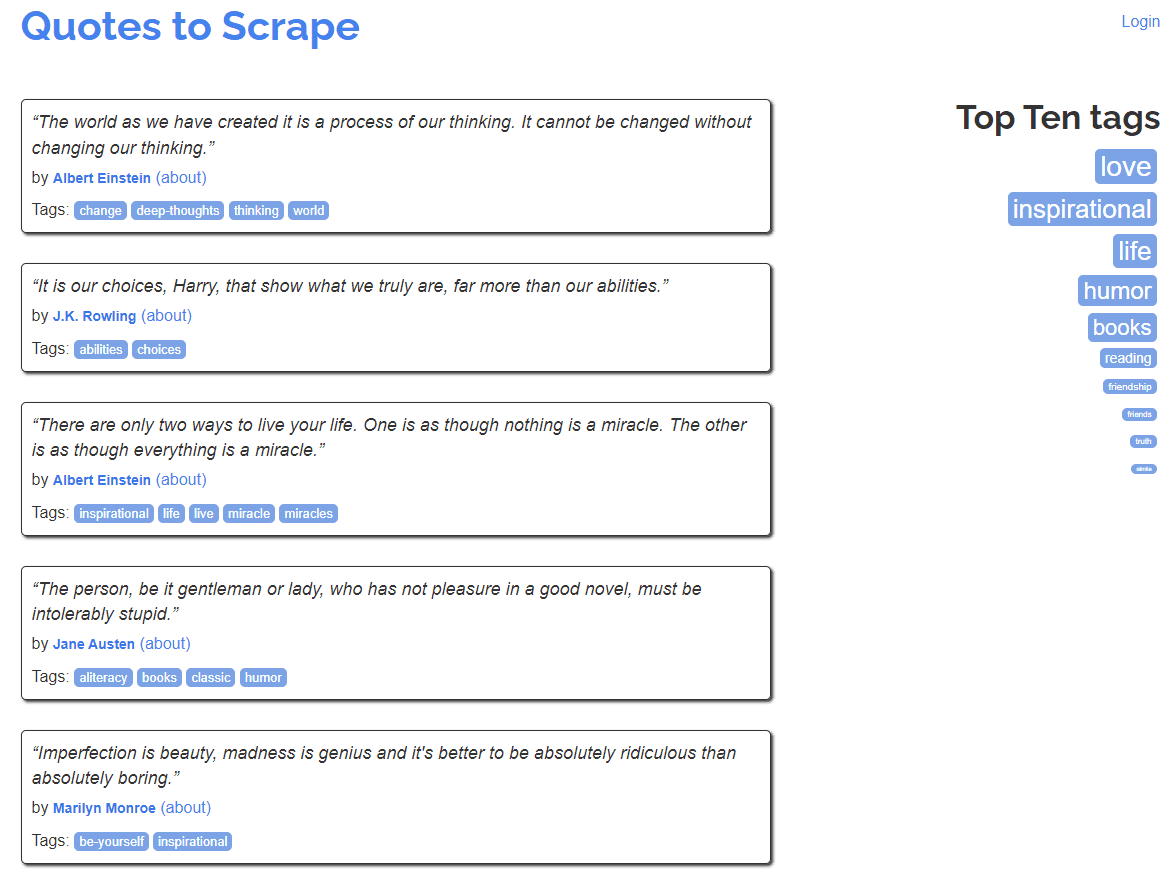
The task at hand for ChatGPT involves crawling through each page and storing the quotes, quote author, and associated tags in a structured format.
I will delineate two distinct methodologies; the first is conducive for smaller projects, whereas the latter is suited for larger-scale projects.
Implementing the Scraper ChatGPT Plugin
Having activated the ChatGPT plugin, proceed to the plugin store and enter “scraper” in the search field.
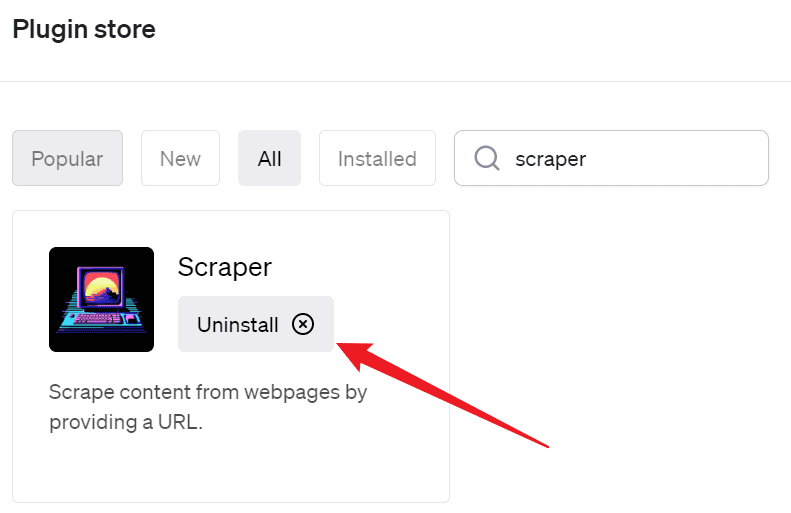
Upon locating the plugin, click the “Install” button to initiate its installation. For me, since I have it installed already, the option available is “Uninstall”.
Post the activation of the Scraper plugin, I relayed the following prompt to ChatGPT:
Please scrape the website http://quotes.toscrape.com/ and retrieve the following information from each page: page number, quote, quotee, tags. Additionally, please navigate to the next page by locating the next button and repeat the process. Once you have scraped all the data, please organize it in a table format. Please provide the final output as tables without explaining the steps involved in the process.
In this prompt, I provided explicit instructions to ChatGPT, delineating the websites it needs to crawl and the specific fields it has to store. I further directed ChatGPT to navigate to the subsequent page and repeat the process.
Considering the voluminous data to be crawled and ChatGPT’s word count limitation, I restricted its output to the table alone, without any elaboration on the task’s execution.
Ultimately, ChatGPT produced a table with 100 rows. Due to the word limit, it had to divide the output into three to four parts before presenting the complete table. I simply had to press the continue button whenever it paused. The following image captures the entire output.
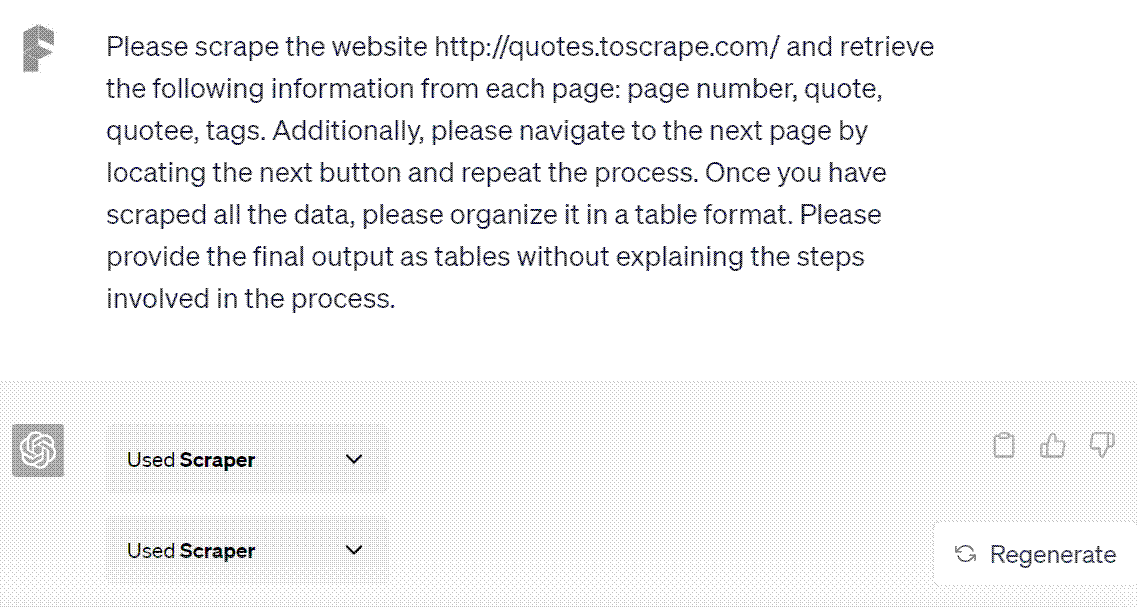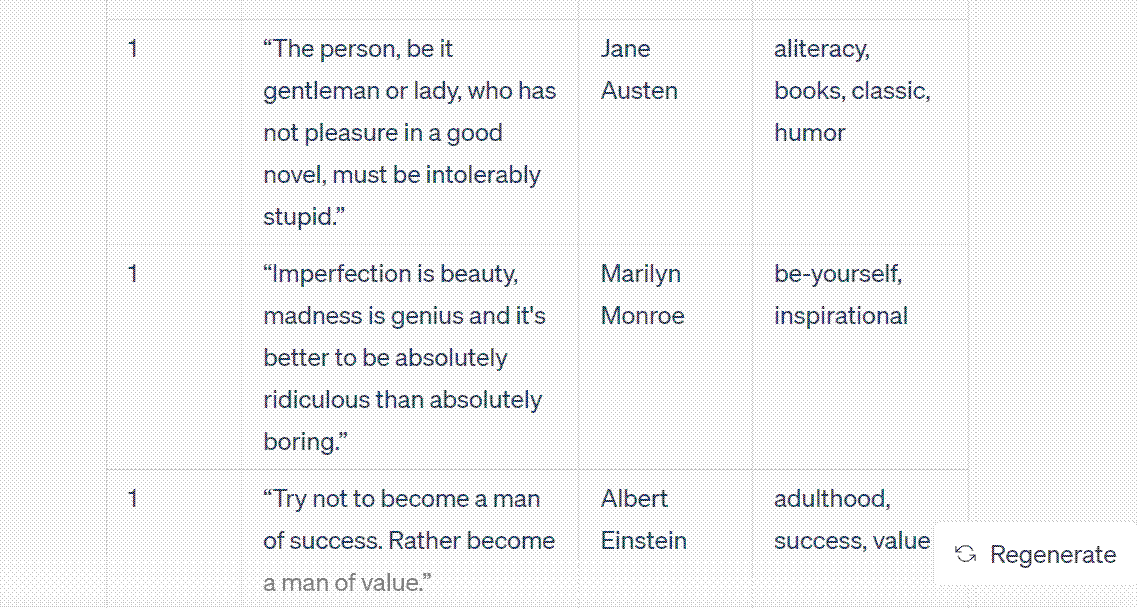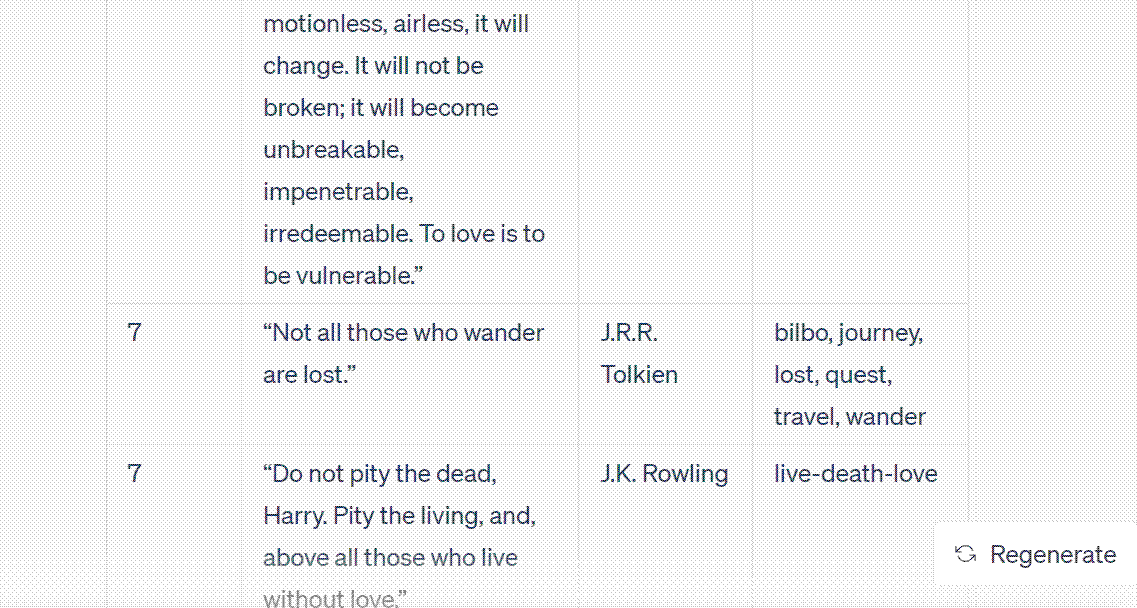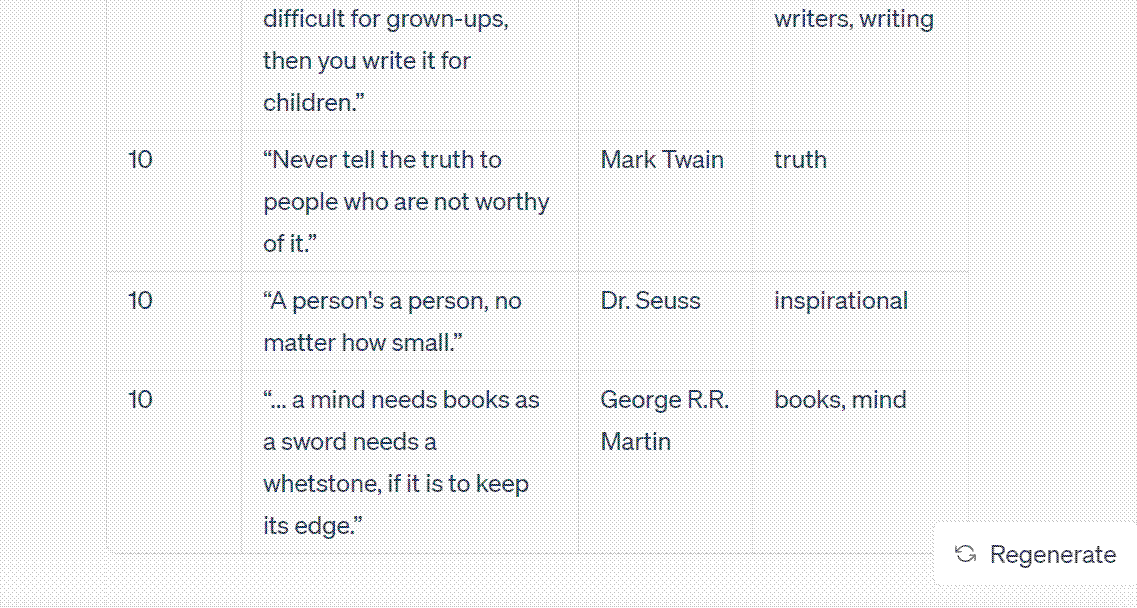
In scenarios with lesser data output, you could directly copy and paste it into Excel. Alternatively, plugins that can produce CSV tables, such as A+ Doc Maker or CSV Exporter, can be employed to directly save the results into a CSV file.
However, these two plugins could not handle the large amount of data I sought to output, precluding the generation of a CSV file. To circumvent this, I utilized an online conversion tool to transform it into a CSV file.
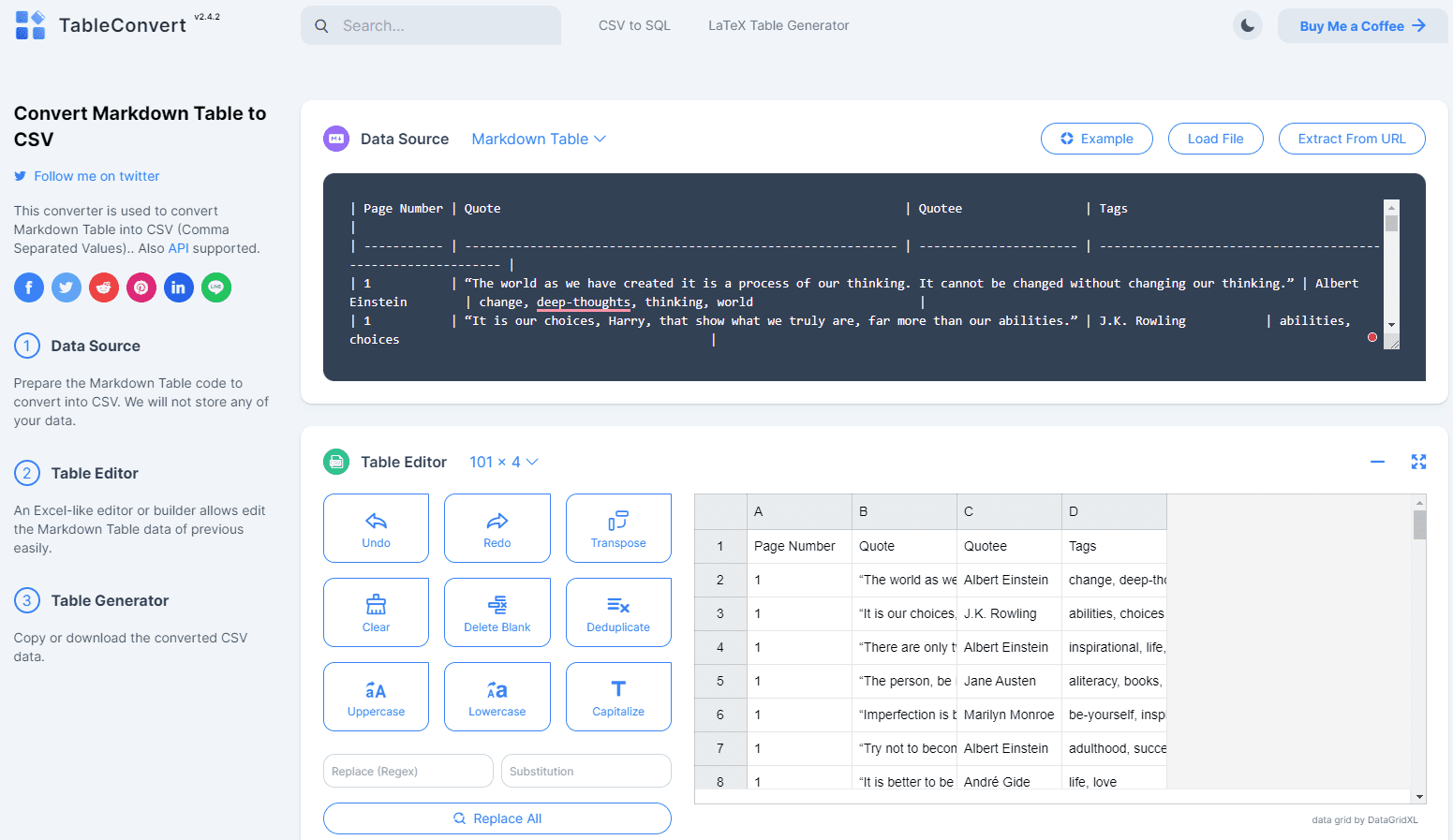
The Code Interpreter can be another viable option for conversion.
Leveraging the Noteable ChatGPT Plugin
Previously, I penned an article on utilizing Noteable for data analysis. However, it also proves to be an invaluable tool for website crawling, especially in handling substantial crawler projects.
As with the previous plugin, you can install the Noteable plugin by searching for “noteable” in the plugin store and clicking “Install”.
Upon installation, you will encounter a login prompt. Once you create a free account and sign in, you will gain access to a dedicated Noteable cloud space.
This cloud space functions independently of ChatGPT, with all code outputs and files from ChatGPT housed in your cloud space. This eliminates the need for outputting Markdown tables and subsequent conversion into Excel or CSV, as outlined in the previous method.
This strategy is particularly beneficial for large-scale projects. For instance, should you wish to crawl and output tens of thousands of data rows to ChatGPT, you would inevitably surpass its word limit, compelling ChatGPT to split the output over several instances.
Noteable, on the other hand, assists you in writing the code, directly crawling the website, and generating the desired file containing the harvested data.
I assigned Noteable the aforementioned task and submitted the following prompt:
Create a project call “Web Scraper” and scrape the website http://quotes.toscrape.com/. Retrieve the following information from each page: page number, quote, quotee, tags. Additionally, please navigate to the next page by locating the next button and repeat the process. Once you have scraped all the data, please organize it in a table format and save it as “quotes.xlsx”.
Noteable structures your tasks into projects, with each project encompassing code and files. On instructing ChatGPT to create a project titled “Web Scrape” for me, it was promptly generated within the Noteable cloud space.
Upon the task’s completion by ChatGPT, two files were observable in the project. web_scraper.py is a notebook that ChatGPT auto-generated, documenting the scraper code.

quotes.xlsx contains the data crawled from the website, and can be directly downloaded from within Noteable.

In cases where the website spans tens of thousands of pages, Noteable processes them swiftly, courtesy of its computing resources that operate independently of ChatGPT. Moreover, if you opt for a paid subscription to Noteable, you can avail of superior computing resources:
- Medium: 2 vCPU, 7.5 GB RAM
- Large: 4 vCPU, 15.0 GB RAM
- Extra Large: 7.5 vCPU, 29.0 GB RAM
- Small (GPU): 2 vCPU, 10.0 GB RAM
- Medium (GPU): 6 vCPU, 26.0 GB RAM
Conclusion
The two methodologies outlined in this article come with their respective merits and demerits.
Employing the Scrape ChatGPT plugin offers a quick and uncomplicated process, obviating the need to register for an account on a third-party platform, with all operations carried out within ChatGPT. Nonetheless, it is hindered by ChatGPT’s word limit, thus limiting its efficacy in conjunction with other plugins to directly output substantial amounts of data into a file.
On the contrary, using Noteable circumvents the restrictions imposed by ChatGPT, enabling the direct storage of the extensive amount of crawled data in files within the Noteable platform. However, this necessitates the creation of a free Noteable account and performing some rudimentary operations within the Noteable platform.
Yet, the crux of the matter remains that ChatGPT significantly reduces the entry barrier for website crawling, simplifying the process for individuals unfamiliar with coding. They can now crawl copious amounts of data utilizing their natural human language skills. Historically, website crawling necessitated specifying element locations in code, such as page buttons or fields to be crawled. Presently, a mere instruction to ChatGPT regarding the desired field and page flip will have it intelligently identify the element location, enhancing convenience significantly.





